reading-notes
Readings: Game of Greed 1
How to use Random Module
Dictionary:
- Randint - Randint accepts two parameters: a lowest and a highest number. The first value should be less than the second.
print random.randint(0, 5) - Choice - Generate a random value from the sequence sequence.
random.choice( ['red', 'black', 'green'] ). - Shuffle - shuffles the elements in list in place, so they are in a random order.
from random import shuffle x = [[i] for i in range(10)] shuffle(x) - Randrange - Generate a randomly selected element from range(start, stop, step)
import random for i in range(3): print random.randrange(0, 101, 5)
What is Risk Analysis
The probability of any unwanted incident is defined as Risk. In Software Testing, risk analysis is the process of identifying the risks in applications or software that you built and prioritizing them to test. After that, the process of assigning the level of risk is done. The categorization of the risks takes place, hence, the impact of the risk is calculated.
Why use Risk Analysis?
Risk analysis allows you to identify risks to your software and other software prior to build/implementation. When a test plan has been created, risks involved in testing the product are to be taken into consideration along with the possibility of the damage they may cause to your software along with solutions.
Possible risks might include:
- Use of new hardware
- Use of new technology
- Use of new automation tool
- The sequence of code
- Availability of test resources for the application
Certain Risks are unavoidable:
- The time that you allocated for testing
- A defect leakage due to the complexity or size of the application
- Urgency from the clients to deliver the project
- Incomplete requirements
Steps to follow:
- Conduct Risk Assessment review meeting
- Use maximum resources to work on high-risk areas
- Create a Risk Assessment database for future use
- Identify and notice the risk magnitude indicators: high, medium, low.
Magnitude Indicators Explained:
-
High: means the effect of the risk would be very high and non-tolerable. The company might face loss.
-
Medium: it is tolerable but not desirable. The company may suffer financially but there is a limited risk.
-
Low: it is tolerable. There lies little or no external exposure or no financial loss.
Risk Identification:
-
Business Risks: This risk is the most common risk associated with our topic. It is the risk that may come from your company or your customer, not from your project.
-
Testing Risks: You should be well acquainted with the platform you are working on, along with the software testing tools being used.
-
Premature Release Risk: a fair amount of knowledge to analyze the risk associated with releasing unsatisfactory or untested software is required
-
Software Risks: You should be well versed with the risks associated with the software development process.
Risk assessment
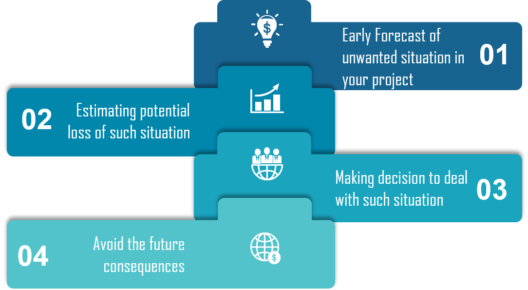
The perspective of Risk Assessment:
-
Effect – To assess risk by Effect. In case you identify a condition, event or action and try to determine its impact.
-
Cause – To assess risk by Cause is opposite of by Effect. Initialize scanning the problem and reach to the point that could be the most probable reason behind that.
-
Likelihood – To assess risk by Likelihood is to say that there is a probability that a requirement won’t be satisfied.
How to perform Risk Analysis?
Steps to perform risk analysis:
-
Searching the risk
-
Analyzing the impact of each individual risk
-
Measures for the risk identified
Big O Notation (Video)
- Constant time =
O(1) - Linear Time =
O(n)
If you have two differnt steps in your algorithm, you need to add up these steps.
O(n) means that the time is derived from the size of the input data.
4 keys to keep in mind when calculating Big-O:
- Different steps need to be added
- Drop constant values
- Different inputs => different variables = Drop non-dominate terms
Python Random
The functions supplied by this module are actually bound methods of a hidden instance of the random.Random class. You can instantiate your own instances of Random to get generators that don’t share state.
Class Random can also be subclassed if you want to use a different basic generator of your own devising: in that case, override the random(), seed(), getstate(), and setstate() methods. Optionally, a new generator can supply a getrandbits() method — this allows randrange() to produce selections over an arbitrarily large range.
The random module also provides the SystemRandom class which uses the system function os.urandom() to generate random numbers from sources provided by the operating system.
Bookkeeping functions
-
random.getstate() - Return an object capturing the current internal state of the generator. This object can be passed to
setstate()to restore the state. -
random.setstate(state) - state should have been obtained from a previous call to
getstate(), andsetstate()restores the internal state of the generator to what it was at the timegetstate()was called.
Functions for bytes
- random.randbytes(n) - Generate
nrandom bytes.This method should not be used for generating security tokens. Use secrets.token_bytes() instead.
Functions for integers
-
random.randrange(stop)/random.randrange(start, stop[, step]) - Return a randomly selected element from range(start, stop, step). This is equivalent to choice(range(start, stop, step)), but doesn’t actually build a range object.
-
random.randint(a, b) - Return a random integer N such that a <= N <= b. Alias for randrange(a, b+1).
-
random.getrandbits(k) - Returns a non-negative Python integer with k random bits. This method is supplied with the MersenneTwister generator and some other generators may also provide it as an optional part of the API. When available, getrandbits() enables randrange() to handle arbitrarily large ranges.
Functions for sequences
-
random.choice(seq) - Return a random element from the non-empty sequence seq. If seq is empty, raises IndexError.
-
random.choices(population, weights=None, *, cum_weights=None, k=1) - Return a k sized list of elements chosen from the population with replacement. If the population is empty, raises IndexError.
-
random.shuffle(x[, random]) - Shuffle the sequence x in place.
-
random.sample(population, k, *, counts=None) - Return a k length list of unique elements chosen from the population sequence or set. Used for random sampling without replacement.
Real-valued distributions
-
random.random() Return the next random floating point number in the range [0.0, 1.0).
-
random.uniform(a, b) - Return a random floating point number N such that a <= N <= b for a <= b and b <= N <= a for b < a.
The end-point value b may or may not be included in the range depending on floating-point rounding in the equation a + (b-a) * random().
-
random.triangular(low, high, mode) - Return a random floating point number N such that low <= N <= high and with the specified mode between those bounds. The low and high bounds default to zero and one. The mode argument defaults to the midpoint between the bounds, giving a symmetric distribution.
-
random.betavariate(alpha, beta) - Beta distribution. Conditions on the parameters are alpha > 0 and beta > 0. Returned values range between 0 and 1.
-
random.expovariate(lambd) - Exponential distribution. lambd is 1.0 divided by the desired mean. It should be nonzero. (The parameter would be called “lambda”, but that is a reserved word in Python.) Returned values range from 0 to positive infinity if lambd is positive, and from negative infinity to 0 if lambd is negative.
-
random.gammavariate(alpha, beta) - Gamma distribution. (Not the gamma function!) Conditions on the parameters are alpha > 0 and beta > 0.
-
random.gauss(mu, sigma) - Gaussian distribution. mu is the mean, and sigma is the standard deviation. This is slightly faster than the normalvariate() function defined below.
-
random.lognormvariate(mu, sigma) - Log normal distribution. If you take the natural logarithm of this distribution, you’ll get a normal distribution with mean mu and standard deviation sigma. mu can have any value, and sigma must be greater than zero.
-
random.normalvariate(mu, sigma) - Normal distribution. mu is the mean, and sigma is the standard deviation.
-
random.vonmisesvariate(mu, kappa) - mu is the mean angle, expressed in radians between 0 and 2pi, and kappa is the concentration parameter, which must be greater than or equal to zero. If kappa is equal to zero, this distribution reduces to a uniform random angle over the range 0 to 2pi.
-
random.paretovariate(alpha) - Pareto distribution. alpha is the shape parameter.
-
random.weibullvariate(alpha, beta) - Weibull distribution. alpha is the scale parameter and beta is the shape parameter.
Alternative Generator
- class random.Random([seed]) - Class that implements the default pseudo-random number generator used by the random module.
Deprecated since version 3.9: In the future, the seed must be one of the following types: NoneType, int, float, str, bytes, or bytearray.
- class random.SystemRandom([seed]) - Class that uses the os.urandom() function for generating random numbers from sources provided by the operating system. Not available on all systems. Does not rely on software state, and sequences are not reproducible. Accordingly, the seed() method has no effect and is ignored. The getstate() and setstate() methods raise NotImplementedError if called.
Notes on Reproducibility
Sometimes it is useful to be able to reproduce the sequences given by a pseudo-random number generator. By re-using a seed value, the same sequence should be reproducible from run to run as long as multiple threads are not running.
Most of the random module’s algorithms and seeding functions are subject to change across Python versions, but two aspects are guaranteed not to change:
-
If a new seeding method is added, then a backward compatible seeder will be offered.
-
The generator’s random() method will continue to produce the same sequence when the compatible seeder is given the same seed.
What is Dependency Injection
In software engineering, dependency injection is a technique whereby one object (or static method) supplies the dependencies of another object. A dependency is an object that can be used (a service).
When class A uses some functionality of class B, then its said that class A has a dependency of class B.
Transferring the task of creating the object to someone else and directly using the dependency is called dependency injection.

Why should I use dependency injection?
Let’s say we have a car class which contains various objects such as wheels, engine, etc.
Here the car class is responsible for creating all the dependency objects. Now, what if we decide to ditch MRFWheels in the future and want to use Yokohama Wheels?
We will need to recreate the car object with a new Yokohama dependency. But when using dependency injection (DI), we can change the Wheels at runtime (because dependencies can be injected at runtime rather than at compile time).
You can think of DI as the middleman in our code who does all the work of creating the preferred wheels object and providing it to the Car class.
It makes our Car class independent from creating the objects of Wheels, Battery, etc.
There are basically three types of dependency injection:
-
constructor injection: the dependencies are provided through a class constructor.
-
setter injection: the client exposes a setter method that the injector uses to inject the dependency.
-
interface injection: the dependency provides an injector method that will inject the dependency into any client passed to it. Clients must implement an interface that exposes a setter method that accepts the dependency.
Now its the dependency injection’s responsibility to:
- Create the objects
- Know which classes require those objects
- And provide them all those objects
Benefits of using DI
- Helps in Unit testing.
- Boiler plate code is reduced, as initializing of dependencies is done by the injector component.
- Extending the application becomes easier.
- Helps to enable loose coupling, which is important in application programming.
Disadvantages of DI
- It’s a bit complex to learn, and if overused can lead to management issues and other problems.
- Many compile time errors are pushed to run-time.
- Dependency injection frameworks are implemented with reflection or dynamic programming. This can hinder use of IDE automation, such as “find references”, “show call hierarchy” and safe refactoring.
Reference Material: (Libraries and Frameworks that implement DI)